First of all, what’s the differences between FixedDocument and FlowDocument and why we can convert FlowDocument into FixedDocument easily but not vice verse? Let’s try to understand
What is FixedDocument? FixedDocument is a host for portable, high fidelity, fixed-format document with read access for user text selection, keyboard navigation, and search (MSDN). Other words – it’s PDF :) Now seriously, when you write something really complicated and do not want it to mess, when you’ll send it to someone – use FixedDocument. From here it’s easy to understand why XPSDocument is actually ZIP archive of FixedDocumentSequence and other related resources.
What it FlowDocument? Flow documents are designed to optimize viewing and readability. Rather than being set to one predefined layout, flow documents dynamically adjust and reflow their content based on run-time variables such as window size, device resolution, and optional user preferences. In addition, flow documents offer advanced document features, such as pagination and columns. This topic provides an overview of flow documents and how to create them. (MSDN). Other words it will not mess, but it is adaptive for your reader. It has no “hard-coded” cuts, however it formatted. So, as for me, FlowDocument is better.
This is very cool. Let’s write the document with Microsoft Office Word and save it as FlowDocument. It make our document very adaptive and easy for reading. Well, that’s the problem. All you may do is to save (actually print) Word document as XPS file.
Now what. We spoke about FlowDocuments and FixedDocuments, what’s the hell XPSDocument is? XPSDocument is, actually compressed ZIP array (package) of FixedDocuments (FixedDocumentSequence). So we have no other chance, but try to make FixedDocuments more adaptive. Other words - convert them into FlowDocuments. Let’s start
As I wrote earlier, XPSDocument is actually package. We should first read it (I already wrote about how to create XPSDocument in memory), so we should first of all create it from the package, and then enumirate all FixedDocuments inside the package and after it all FixedPages inside each FixedDocument
XpsDocument _doc = new XpsDocument(pkg, CompressionOption.Fast, pack);
IXpsFixedDocumentSequenceReader fixedDocSeqReader = _doc.FixedDocumentSequenceReader;foreach (IXpsFixedDocumentReader docReader in fixedDocSeqReader.FixedDocuments)
{
foreach (IXpsFixedPageReader fixedPageReader in docReader.FixedPages)
{
Well, what is FixedPage? FixedPage provides the content for a high fidelity, fixed-format page. (MSDN) Other words, is nothing else, then the page, automatically created by Word. We do not really need it – remember, we want it adaptive
Now, when we have FixedPage (it’s actually IXpsFixedPage), we should read the information inside it. How to do it? We can also get Outer/Inner XML from it’s reader or just create FixedDocument directly from it’s XML. I’ll use string option (why? keep reading). So, while we can read, just get all OuterXml and put it into regular string. Then we can use XamlReader to read this string and convert it into FixedPage
while (fixedPageReader.XmlReader.Read())
{
string page = fixedPageReader.XmlReader.ReadOuterXml();
FixedPage fp = XamlReader.Load(new MemoryStream(Encoding.Default.GetBytes(page))) as FixedPage;
The next very reasonable question is: Why not just use GetFixedDocumentSequence to retrieve all references for PageContent and then get FixedPage directly from the root of the PageContent in order to save heavy XamlReader usage. Like this:
foreach (DocumentReference dr in _doc.GetFixedDocumentSequence().References)
{
foreach (PageContent pc in dr.GetDocument(false).Pages)
{
FixedPage fp = pc.GetPageRoot(false);
BlockUIContainer cont = new BlockUIContainer();
cont.Child = fp;
fdoc.Blocks.Add(cont);
}
}
Well, How often you saw following error:”Specified element is already the logical child of another element. Disconnect it first.”? That’s exactly the problem. Even using this method, you should Clone XAML object. How to do it (you really do not know?) – XamlReader(XamlWriter). So you’ll save nothing (even loss some)
So far so good. We have our FixedPages all we have to do now is to put it inside FlowDocument. Am I right? Not so fast. First, this is regular WPF control, so we should use BlockUIContainer to place it inside flow document
BlockUIContainer cont = new BlockUIContainer();
cont.Child = fp;
fdoc.Blocks.Add(cont);
Now let’s run the program. What’s the hell is “Cannot locate resource 'documents/1/resources/fonts/e87fcd50-6c36-40ca-928a-dd5e97fd0c52.odttf'”? What is ODTTF what files? I did not put any files inside my Word document. Let’s see the result page. This will looks like this:
<FixedPage Width="816" Height="1056" xmlns="http://schemas.microsoft.com/xps/2005/06" xml:lang="und">
<Glyphs Fill="#ff000000" FontUri="/Documents/1/Resources/Fonts/E87FCD50-6C36-40CA-928A-DD5E97FD0C52.odttf" FontRenderingEmSize="14.6921" StyleSimulations="None" OriginX="96" OriginY="109.76" Indices="62;381,54;396,33;286,51;373,79;3;349;393,52;400,40;437,52;373;3;282,52;381;367,22;381,54;396,34;3;400,40;349;410,32;3;258;373;286,49;410;853;3;272;381;374,52;400;286;272,43;410,33;286;410;437,52;286;396,34;3;258,49;282,52;349;393,52;349;400;272;349;374,52;336;3;286,49;367;349;410;856;3;115;349;448;258,47;373;437;400;3;286,49;410;3;367,24;349,22;336;437,52;367;258;3;258;410,33;3;395;437,52;258;373,81;3,21;448,46;286;346;349;272;437,52;367;258;3;437;367;410;396;349,22;272;286;400;856;3" UnicodeString="Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Vivamus et ligula at quam vehicula ultrices." />
<Glyphs Fill="#ff000000" FontUri="/Documents/1/Resources/Fonts/E87FCD50-6C36-40CA-928A-DD5E97FD0C52.odttf" FontRenderingEmSize="14.6921" StyleSimulations="None" OriginX="96" OriginY="130.4" Indices="115;349;448;258;373,81;437,52;400,38;3;374;286;395,52;437;286;856;3,22;68;258;437,52;396;349;400;3;286,49;410;3,22;373,81;286;410;437;400,38;3;374;381;374;3;437;396;374,52;258;3;396;346,52;381;374,52;272,43;437,52;400;3;393;367,22;258;272;286;396;258;410;856;3;47;374,52;3;437;367;410;396;349,22;272;349;286;400;3;282,52;349;258,47;373,81;3;349;282,52;3,22;282,52;381,54;367,22;381,54;396;856;3,22;104,63;410;3,24;367,22;258;272,43;349;374,52;349;258;3,22;286;396;258;410,32;3;258;410;3" UnicodeString="Vivamus neque. Mauris et metus non urna rhoncus placerat. In ultricies diam id dolor. Ut lacinia erat at" />
So, e87fcd50-6c36-40ca-928a-dd5e97fd0c52.odttf is actually font. Let’s just save it as font. In order to do it, we should first get all from our XPSPackage. Then save it as stream and change links to our font file. This is easy
foreach (XpsFont font in fixedPageReader.Fonts)
{
…using (Stream stm = font.GetStream())
{
using (FileStream fs = new FileStream(path, FileMode.Create))
{
byte[] dta = new byte[stm.Length];
stm.Read(dta, 0, dta.Length);
fs.Write(dta, 0, dta.Length);
}
}
Good. Now we have file, located in place we can refer to. Let’s load it. WTF is “file:///E87FCD50-6C36-40CA-928A-DD5E97FD0C52.odttf' file does not conform to the expected file format ”? What you expected for? This is font. I promise, I SWEAR! Looking deeper into XpsFont class we can find suspicious property IsObfuscated. What is it? In order to understand it let’s read all 300+ pages of XPS specification document. In chapter 2.1.7.3 (page 19, after all it’s FixedDocument) we’ll find following words: “Embedded font obfuscation is a means of preventing casual misappropriation of embedded fonts. Specifically, embedded font obfuscation prevents end-users from using standard ZIP utilities to extract fonts from XPS Document files and install them on their systems. Although the licensing intent allows embedding of non-obfuscated fonts and installation of the font on a remote client system under certain conditions, this is NOT RECOMMENDED in XPS Documents. Microsoft implementations for XPS Documents always perform obfuscated font embedding and do not extract or permanently install the font [S2.19]. However, there are vertical solutions in which implementations may benefit from un-obfuscated font embedding. In these cases, implementations could omit obfuscation or extract and install the embedded font. “.
Well, how to hack it?
- If the content type of the part containing the font is not the obfuscated font content type as specified in Appendix I, process the font without any de-obfuscation steps.
- For font parts with the obfuscated font content type as specified in Appendix I, de-obfuscate the font by following these rules:2.
- Remove the extension from the last segment of the name of the part containing the font.
- Convert the remaining characters of the last segment to a GUID using the byte ordering described above.
- Perform an XOR operation on the first 32 bytes of the binary data of the obfuscated font part with the array consisting of the bytes referred to by the placeholders B37, B36, B35, B34, B33, B32, B31, B30, B20, B21, B10, B11, B00, B01, B02, and B03, in that order and repeating the array once. The result is a non-obfuscated font.
- Use the non-obfuscated font for the duration of the document processing, but do not leave any local or otherwise user-accessible copy of the non-obfuscated font.
Very well. Let’s write such attached method (I love them)
public static void SaveToDisk(this XpsFont font, string path)
{
using (Stream stm = font.GetStream())
{
using (FileStream fs = new FileStream(path, FileMode.Create))
{
byte[] dta = new byte[stm.Length];
stm.Read(dta, 0, dta.Length);
if (font.IsObfuscated)
{
string guid = new Guid(font.Uri.GetFileName().Split('.')[0]).ToString("N");
byte[] guidBytes = new byte[16];
for (int i = 0; i < guidBytes.Length; i++)
{
guidBytes[i] = Convert.ToByte(guid.Substring(i * 2, 2), 16);
}for (int i = 0; i < 32; i++)
{
int gi = guidBytes.Length - (i % guidBytes.Length) - 1;
dta[i] ^= guidBytes[gi];
}
}
fs.Write(dta, 0, dta.Length);
}
}
}
Now we can save and load obfuscated XPS Fonts. What’s next? Replace it’s locations inside FixedPages. In order to do this, we’ll write another set of attached methods. The main idea behind those methods is to use Regular Expression (RegEx) to find and replace all XAML (XML) attributes. This is the king: “{0}(?:\s*=\s*(""[^""]{1}""|[^\s>]*))?”
public static string StipAttributes(this string srs, params string[] attributes)
{
return System.Text.RegularExpressions.Regex.Replace(srs,
string.Format(@"{0}(?:\s*=\s*(""[^""]*""|[^\s>]*))?",
string.Join("|", attributes)),
string.Empty,
System.Text.RegularExpressions.RegexOptions.IgnoreCase | System.Text.RegularExpressions.RegexOptions.Compiled);
}public static string ReplaceAttribute(this string srs, string attributeName, string replacementValue)
{
return System.Text.RegularExpressions.Regex.Replace(srs,
string.Format(@"{0}(?:\s*=\s*(""[^""]*""|[^\s>]*))?", attributeName),
string.Format("{0}=\"{1}\"", attributeName, replacementValue),
System.Text.RegularExpressions.RegexOptions.IgnoreCase | System.Text.RegularExpressions.RegexOptions.Compiled);
}public static string ReplaceAttribute(this string srs, string attributeName, string attributeValue, string replacementValue)
{
return System.Text.RegularExpressions.Regex.Replace(srs,
string.Format(@"{0}(?:\s*=\s*(""[^""]{1}""|[^\s>]*))?", attributeName,attributeValue),
string.Format("{0}=\"{1}\"", attributeName, replacementValue),
System.Text.RegularExpressions.RegexOptions.IgnoreCase | System.Text.RegularExpressions.RegexOptions.Compiled);
}
Now, we can safely create dictionary of old and new font pathes and replace them inside the XAML string we have (now you understand, that string is better, then XML?)
foreach (XpsFont font in fixedPageReader.Fonts)
{
string name = font.Uri.GetFileName();
path = string.Format(@"{0}\{1}", Environment.GetFolderPath(Environment.SpecialFolder.ApplicationData), name);if (!fontList.ContainsKey(font.Uri.OriginalString))
{
fontList.Add(font.Uri.OriginalString, path);
font.SaveToDisk(path);
}
}
…foreach(KeyValuePair<string,string> val in fontList)
{
page = page.ReplaceAttribute("FontUri", val.Key,val.Value);
}
The same thing we’ll do for images
foreach (XpsImage image in fixedPageReader.Images)
{
//here to get images
}
Now the only thing we should do is to collect everything together and see what we have
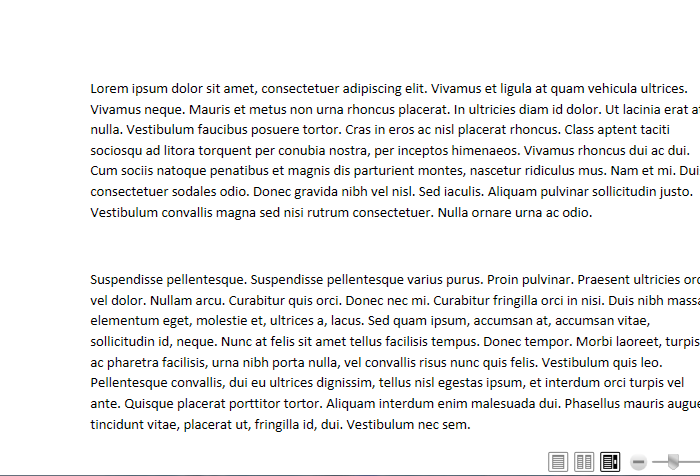
Well it works, but it still is not adaptive enough
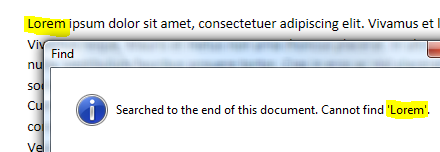
It’s just flow representation of fixed document. You see (I select one element – this is whole BlockUIContainer). Also all texts will be wrapped to “adaptive size”.

What to do? Let’s see another time on FixedPage we got. It uses glyphs to present information. This might be very good, when you do not want to format it. In my case, I want it. I want also be able to search and select separate words. What should I do?
<FixedPage Width="816" Height="1056" xmlns="http://schemas.microsoft.com/xps/2005/06" xml:lang="und">
<Glyphs Fill="#ff000000" FontUri="/Documents/1/Resources/Fonts/E87FCD50-6C36-40CA-928A-DD5E97FD0C52.odttf" FontRenderingEmSize="14.6921" StyleSimulations="None" OriginX="96" OriginY="109.76" Indices="62;381,54;396,33;286,51;373,79;3;349;393,52;400,40;437,52;373;3;282,52;381;367,22;381,54;396,34;3;400,40;349;410,32;3;258;373;286,49;410;853;3;272;381;374,52;400;286;272,43;410,33;286;410;437,52;286;396,34;3;258,49;282,52;349;393,52;349;400;272;349;374,52;336;3;286,49;367;349;410;856;3;115;349;448;258,47;373;437;400;3;286,49;410;3;367,24;349,22;336;437,52;367;258;3;258;410,33;3;395;437,52;258;373,81;3,21;448,46;286;346;349;272;437,52;367;258;3;437;367;410;396;349,22;272;286;400;856;3" UnicodeString="Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Vivamus et ligula at quam vehicula ultrices." />
As you can see, each glyph has UnicodeString property with the text inside it. This what I need. Simple DOM operation and I have all texts from the document. Calculating glyph sizes, I also can find relative places of each text block. This I can make it “Flow and adaptive”.
Want to? Download the source for this article and do it. This is easy part of the sequence. I promise (I also put clues in code).
Have a nice day and be good people.
1 comment:
Note that there's an error in your sample code, which is hidden by the fact that you only have one font in your test document. There is a problem with the regular expression used for attribute replacement, and it causes a FontUri="..." attribute to match for fonts other than the one currently being replaced.
Post a Comment